
- Voyage dans le Deep Learning : Principes et applications
- Présentation du cours
- 1. Introduction au Deep Learning
- 2. L’architecture des réseaux de neurones
- 3. La préparation des données
- 4. Processus d’entraînement
- 5. Défis dans l’entraînement des modèles
- 6. Architectures spécialisées de réseaux
- 7. Enrichir les données grâce à l’augmentation
- 8. Apprentissage par transfert et fine-tuning
- 9. Modèle de détection de phishing (Google collab)
- 10. Conclusion
- Glossaire
Voyage dans le Deep Learning - Principes et applications
Le cours approfondi sur le Deep Learning que j’ai suivi, proposé par NVIDIA, m’a motivé à organiser mes notes de manière structurée et claire. Voici un résumé des notions clés que j’ai retenues. Ce cours est disponible ici.
À la fin de cet article, vous trouverez un notebook Google Colab où je mets en pratique les concepts abordés dans ce cours. J’y développe un modèle capable de détecter les emails de phishing et de prédire si un nouveau message est une tentative de phishing ou non.
Présentation du cours
Le cours est structuré en plusieurs modules, chacun couvrant un aspect essentiel du Deep Learning :
- An Introduction to Deep Learning - 1.5 Hours
- The Theory Behind Neural Networks - 1.5 Hours
- Convolutional Neural Networks - 1.5 Hours
- Data Augmentation and Deployment - 1.5 Hours
- Pre-trained Models - 1.5 Hours
- Recurrent Neural Networks - 1.5 Hours
- Wrap-up and Assessment - 2 Hours
1. Introduction au Deep Learning
Le Deep Learning repose sur des réseaux de neurones à couches multiples capables d’apprendre des motifs complexes à partir de données. L’efficacité de cette technologie pour extraire automatiquement des caractéristiques à partir de données brutes rend possible des applications comme la reconnaissance d’images et de paroles.
Ce qui rend cette technologie si puissante, c’est sa capacité à :
- Traiter des ensembles de données complexes et multidimensionnels.
- Capturer des relations complexes entre différentes variables.
- Exceller dans la reconnaissance de motifs par essais et erreurs.
En entraînant un réseau de neurones à couches multiples avec suffisamment de données et en fournissant au réseau un retour sur ses performances via l’entraînement, le réseau peut identifier, à travers un grand nombre d’itérations, son propre ensemble de conditions lui permettant d’agir de manière correcte.
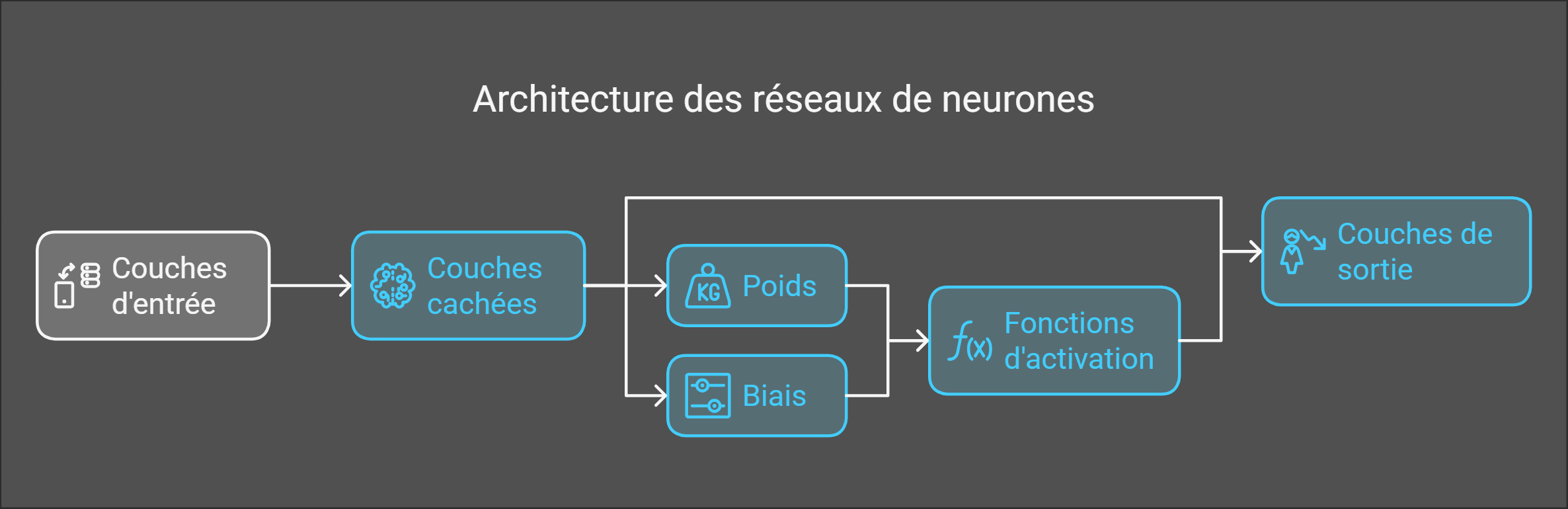
2. L’architecture des réseaux de neurones
- Les couches :
- Couches d’entrée : Reçoivent les données brutes.
- Couches cachées : Effectuent des transformations à l’aide d’opérations linéaires et de fonctions d’activation.
- Couches de sortie : Génèrent des prédictions finales.
Comment les réseaux de neurones prennent-ils des décisions ?
Chaque connexion entre neurones est pondérée par des poids, et des biais sont ajoutés pour ajuster l’activation d’un neurone. Plus un poids est élevé, plus une information a de l’importance dans la décision finale.
- Les biais sont des paramètres appris ajoutés aux neurones.
- Les poids déterminent l’influence des entrées sur les sorties et sont ajustés pendant l’entraînement.
Fonctions d’activation
Les fonctions d’activation introduisent de la non-linéarité dans le réseau, permettant ainsi d’apprendre des relations complexes.
- ReLU (Rectified Linear Unit) : Introduit de la non-linéarité en renvoyant directement l’entrée si elle est positive, sinon zéro.
- Sigmoid : Mappe les entrées dans une plage entre 0 et 1, ce qui est utile pour la classification binaire.
- Tanh (Tangente hyperbolique) : Similaire à Sigmoid, mais avec une sortie entre -1 et 1.
| Fonction | Usage typique | Avantages | Limites |
|---|---|---|---|
| ReLU | Couches cachées | Évite le vanishing gradient | Neurones “morts” (inactifs) |
| Sigmoid | Sortie binaire | Interprétation probabiliste | Sensible au vanishing gradient |
| Tanh | Transformations cachées | Centrée sur zéro | Problème de saturation pour des valeurs extrêmes |
Les tenseurs (tensors)
Ces structures de données multidimensionnelles sont essentielles dans les modèles de Deep Learning. Comparables à des “legos multidimensionnels”, elles sont efficacement traitées par les GPU.
Un vecteur est un tableau à une dimension, une matrice à deux dimensions, et un tenseur à n dimensions. Les frameworks modernes de réseaux de neurones sont conçus pour manipuler ces tenseurs.
Par exemple, un tenseur à trois dimensions peut représenter les pixels d’un écran d’ordinateur, avec des dimensions pour la largeur, la hauteur et le canal de couleur.
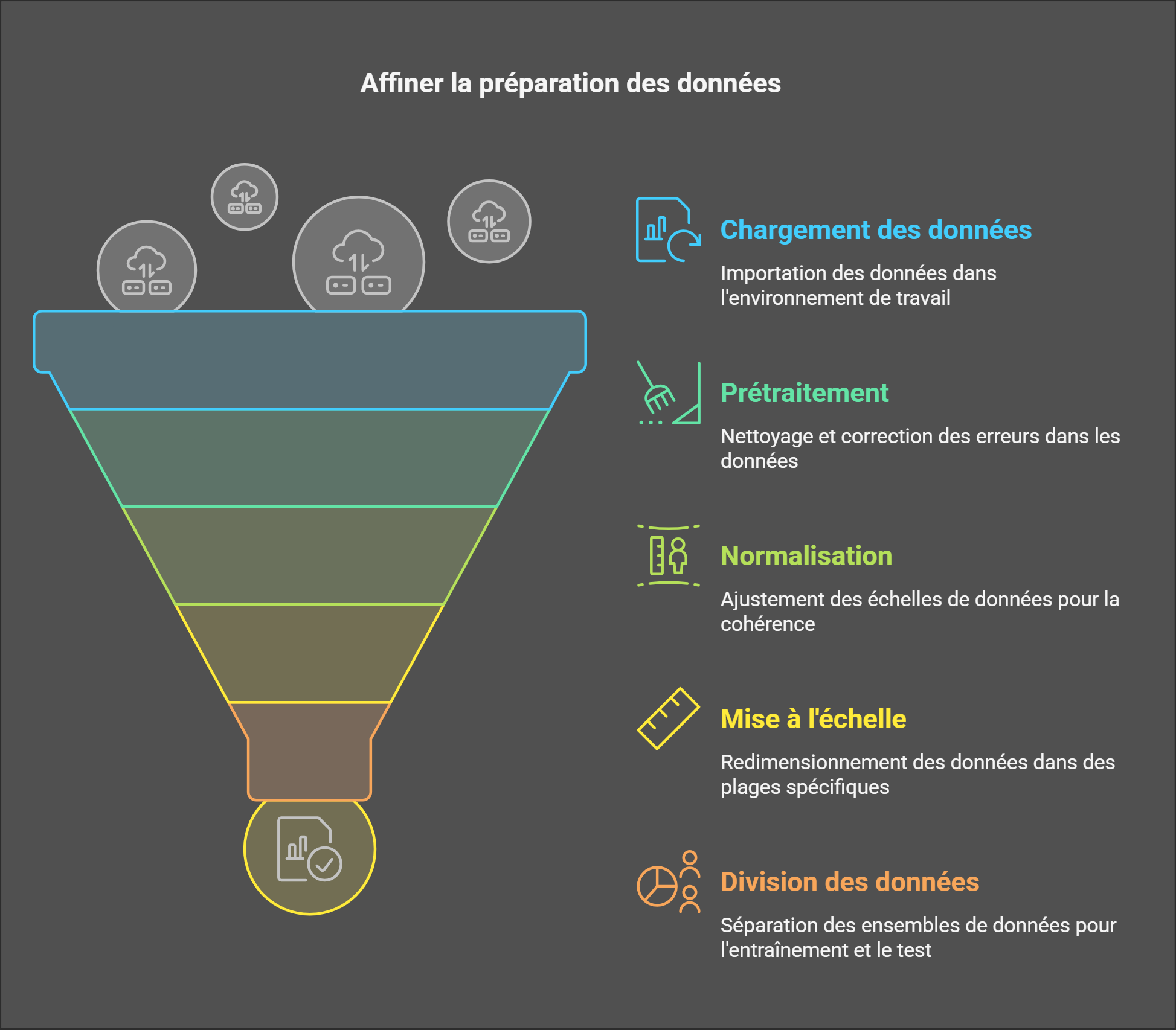
3. La préparation des données
Une grande partie de la réussite en Deep Learning dépend de la qualité des données. Voici les étapes importantes :
- Chargement et prétraitement des données : Cette étape consiste à manipuler efficacement de grands ensembles de données tout en les nettoyant pour éviter des erreurs.
- Techniques de normalisation et de mise à l’échelle :
- Standardisation : Ajuste les données pour qu’elles aient une moyenne de 0 et un écart-type de 1.
- Normalisation : Redimensionne les données dans une plage spécifique, souvent [0, 1].
- Division des données :
- Une répartition 70-15-15 (entraînement, validation, test) est souvent utilisé car il offre un bon équilibre entre apprentissage et évaluation. Cependant, des variantes comme 80-10-10 peuvent être adaptées à des volumes de données différents.
4. Processus d’entraînement
L’entraînement d’un réseau de neurones passe par plusieurs étapes.
4.1 Propagation avant
Les données passent successivement par plusieurs couches, où elles subissent des transformations mathématiques. Chaque couche extrait des caractéristiques de plus en plus abstraites : par exemple, dans une image de chat, les premières couches détectent des bords et des textures, tandis que les couches plus profondes identifient des formes spécifiques comme des yeux ou des pattes.
4.2 Calcul de la perte
La fonction de perte mesure l’écart entre la prédiction du modèle et la valeur réelle attendue. On peut l’imaginer comme un système de correction d’examen : plus la réponse de l’élève diffère du corrigé, plus la pénalité (la perte) est grande. L’objectif est alors de minimiser cette pénalité au fil de l’entraînement.
4.3 Rétropropagation
La rétropropagation permet au réseau de neurones d’apprendre en ajustant ses paramètres. Elle calcule l’erreur entre la prédiction et la valeur attendue, puis remonte le réseau pour ajuster chaque poids en fonction de sa contribution à l’erreur.
4.4 Algorithmes d’optimisation
Algorithme comme qui ajuste les poids pour améliorer progressivement la précision.
- Stochastic Gradient Descent (SGD) : Met à jour les paramètres en fonction des variations des sous-ensembles de données.
- Adam : Ajuste les taux d’apprentissage de manière adaptative, pour chaque paramètre.
| Optimiseur | Avantages | Inconvénients | Usage typique |
|---|---|---|---|
| SGD | Contrôle précis | Sensible au taux d’apprentissage | Modèles simples |
| Adam | Convergence rapide et stable | Paramètres à ajuster | Modèles complexes |
Pour plus d’informations sur les fonctions d’activation, vous pouvez consulter cette page Wikipédia.
4.5 Cycles d’entraînement (Epochs)
Une epoch correspond à un passage complet du modèle sur l’intégralité des données d’entraînement.
- Usage :
- 5-10 epochs suffisent souvent pour des modèles simples ou des données limitées.
- Des centaines d’epochs peuvent être nécessaires pour des architectures complexes.
- Validation : Après chaque epoch, le modèle est évalué sur les données de validation pour suivre sa progression.

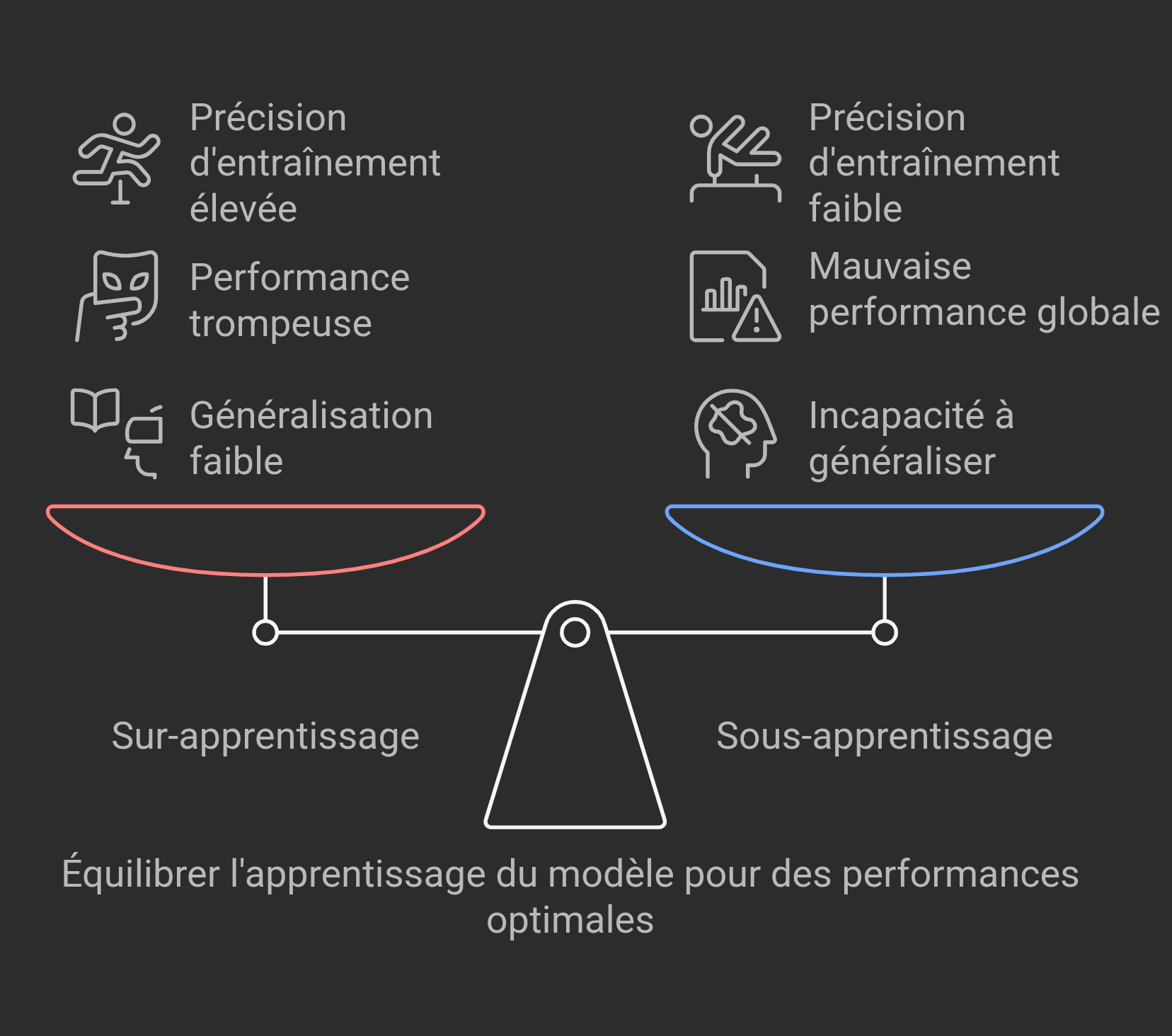
5. Défis dans l’entraînement des modèles
5.1 Sur-apprentissage (Overfitting) :
Si un modèle apprend trop bien les données d’entraînement, il peut avoir du mal à généraliser sur de nouvelles données.
- Symptômes : Nombre excessif d’epochs entraînant une mémorisation du bruit des données. Haute précision en entraînement, faible en validation.
- Solutions :
- Dropout : Désactivation aléatoire de neurones.
- Régularisation L1/L2 : Ajout d’une pénalité sur les poids trop importants du réseau. La régularisation L1 pousse certains poids à devenir nuls (éliminant des connexions), tandis que la L2 réduit proportionnellement tous les poids pour les maintenir à des valeurs modérées.
- Augmentation de données : Génération d’échantillons synthétiques.
- Early Stopping : Interrompre l’entraînement quand la performance en validation se dégrade (ex : après 5 epochs sans amélioration).
5.2 Sous-apprentissage (Underfitting) :
Un modèle sous-apprend lorsqu’il est trop simple pour capturer la complexité des données.
- Symptômes : Faible précision en entraînement et validation. Le modèle est trop simple pour capturer les motifs des données.
- Solutions :
- Complexification du modèle : Ajouter plus de couches ou de neurones pour permettre au modèle de capturer des motifs plus complexes.
- Augmentation de la durée d’entraînement : Augmenter le nombre d’epochs pour permettre au modèle de mieux apprendre les données.
- Réduction de la régularisation : Diminuer les pénalités de régularisation pour permettre au modèle d’ajuster plus librement ses poids.
- Utilisation de fonctions d’activation non linéaires : Introduire des fonctions d’activation non linéaires pour permettre au modèle de capturer des relations plus complexes dans les données.
- Réduction du taux de dropout : Diminuer le taux de dropout pour permettre à plus de neurones de contribuer à l’apprentissage.
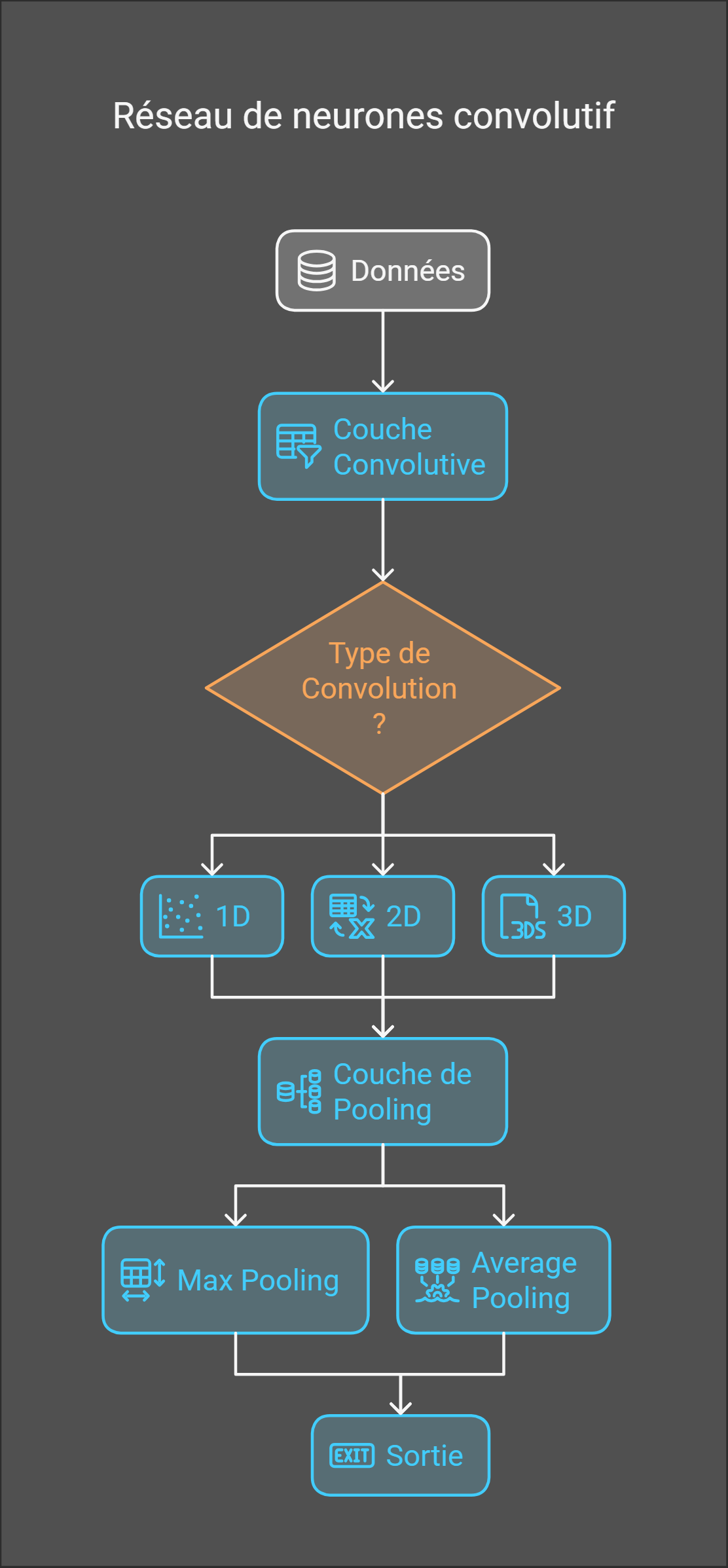
6. Architectures spécialisées de réseaux
6.1. Réseaux Convolutifs ()
Les CNN sont conçus pour traiter des données structurées en grille (images, sons, etc.) en extrayant des motifs hiérarchiques.
6.1.1. Couche Convolutive (Convolutional Layer)
Applique des filtres (masques) pour détecter des motifs spécifiques dans une zone restreinte des données d’entrée.
- Filtres : Matrices de poids appris qui s’adaptent à la dimension des données.
- Exemple : Sur un signal audio, un filtre pourrait détecter les montées rapides d’amplitude. Sur une image, il pourrait repérer les transitions entre zones claires et sombres.
- Paramètres clés :
- Stride : Distance de déplacement du filtre à chaque étape. Par exemple, un stride de 1 signifie que le filtre se déplace d’un pixel à la fois.
- Padding : Ajout de bordures autour de l’image d’entrée pour contrôler la taille de la sortie. Par exemple, un padding de 1 ajoute une bordure d’un pixel de large autour de l’image.
La convolution peut s’appliquer à des données de différentes dimensions :
| Dimension | Exemples d’application |
|---|---|
| 1D | Signaux audio, séries temporelles |
| 2D | Images, cartes de données |
| 3D | Vidéos, imagerie médicale |
| nD | Données à n dimensions |
6.1.2. Couche de Pooling (Pooling Layer)
- Objectif : Réduire la taille des données spatiales tout en conservant les informations importantes, ce qui rend le modèle plus robuste aux variations telles que les rotations et les translations.
- Types :
- Max Pooling : Prend la valeur maximale dans une fenêtre.
- Avantage : Préserve les motifs dominants.
- Average Pooling : Prend la moyenne des valeurs.
- Usage : Atténue le bruit mais perd en précision.
- Max Pooling : Prend la valeur maximale dans une fenêtre.
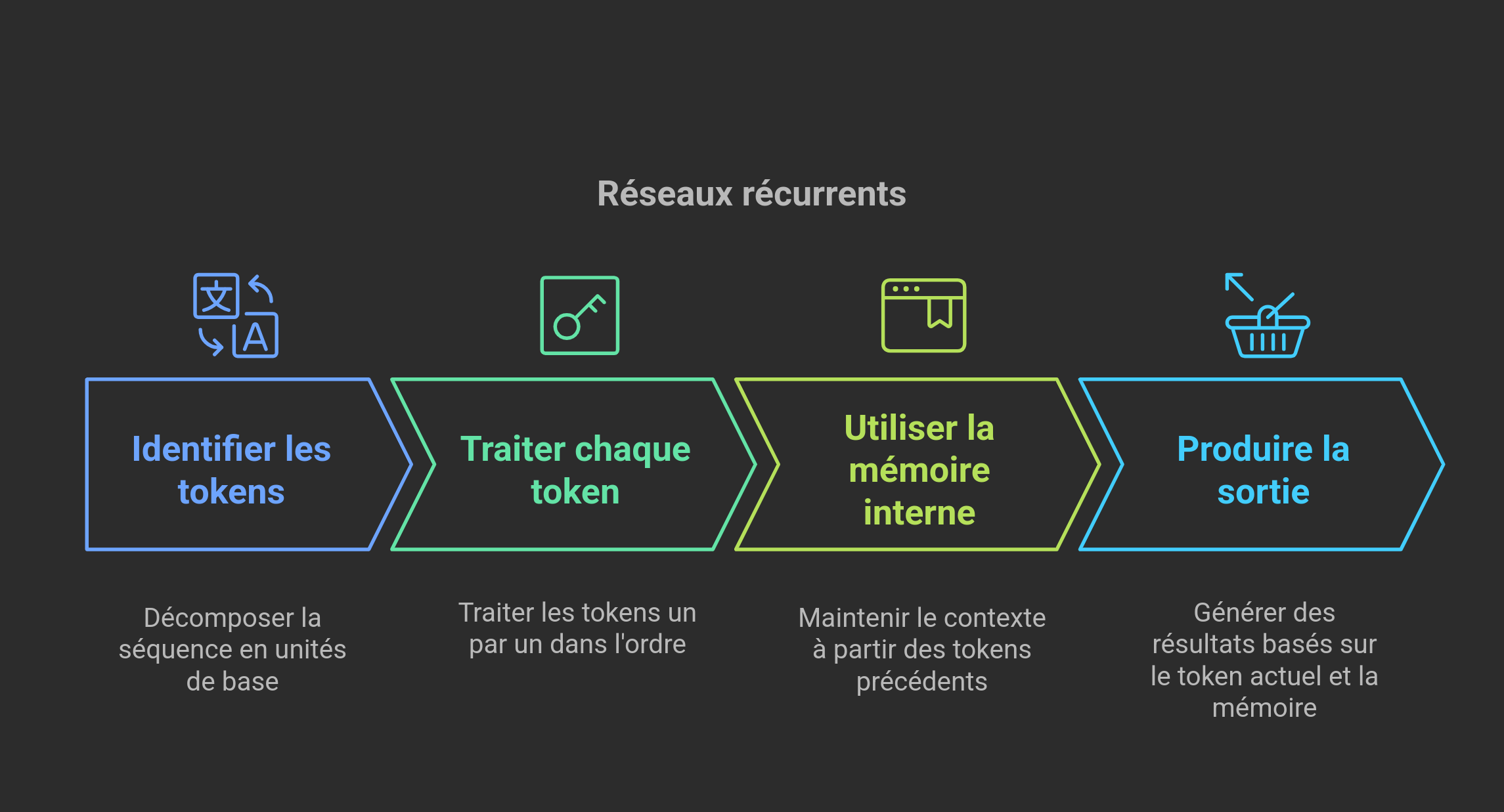
6.2. Les réseaux récurrents (RNN)
Les RNN traitent des séquences de données (texte, audio, vidéo) en maintenant une mémoire interne qui capture le contexte des étapes précédentes.
6.2.1. Traitement séquentiel des tokens
- Token : Unité de base d’une séquence (ex: un mot, un caractère, ou un sous-mot).
- Processus :
- Chaque token est traité pas à pas.
- La sortie à chaque étape dépend du token courant et de la mémoire des tokens précédents.
Exemple de Tokenisation avec OpenAI:
- Phrase : “Le chat noir dort sur le canapé.”
- Tokens : [“Le”, “ chat”, “ noir”, “ dort”, “ sur”, “ le”, “ canapé”, “.”]
7. Enrichir les données grâce à l’augmentation
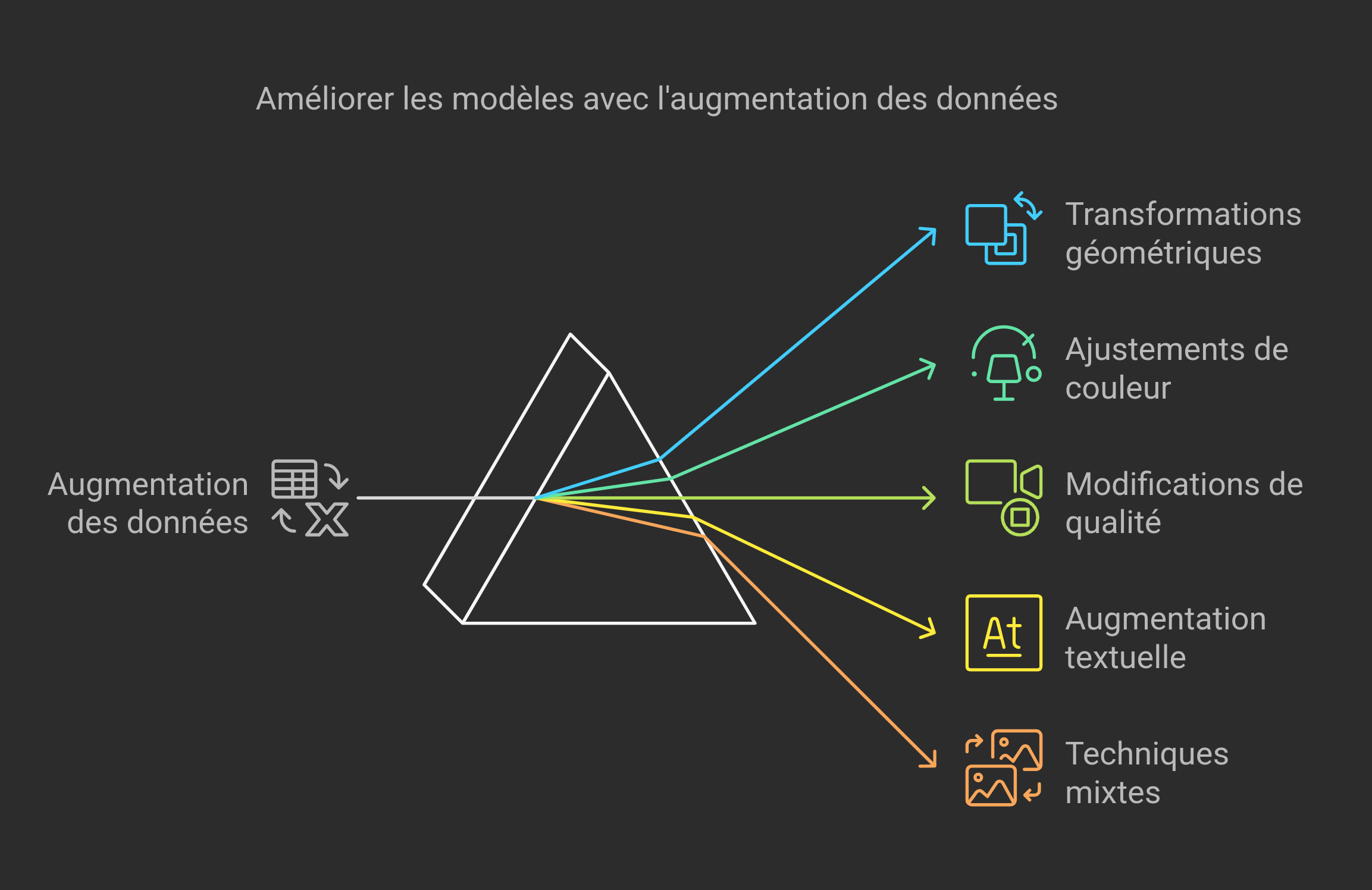
L’augmentation des données est une technique essentielle pour améliorer la performance des modèles en créant des variations artificielles des données existantes. Cela permet d’augmenter la diversité des données d’entraînement et de rendre le modèle plus robuste et généraliste.
-
Transformations géométriques :
- Rotation : Faire pivoter l’image pour varier les angles.
- Zoom : Agrandir ou réduire l’image pour varier les échelles.
- Déplacement : Translater l’image horizontalement ou verticalement.
- Retournement : Inverser l’image horizontalement ou verticalement.
- Cisaillement : Déformer l’image pour simuler des perspectives différentes.
-
Ajustements de couleur :
- Luminosité : Modifier l’intensité lumineuse pour simuler différentes conditions d’éclairage.
- Contraste : Ajuster la différence entre les couleurs claires et foncées.
- Saturation : Modifier l’intensité des couleurs.
- Balance des blancs : Ajuster la teinte globale de l’image pour simuler différentes températures de couleur.
-
Modifications de qualité :
- Ajout de bruit : Introduire du bruit aléatoire pour simuler des conditions de capture imparfaites.
- Flou : Appliquer un flou pour simuler des images prises avec une mise au point imparfaite.
- Compression : Réduire la qualité de l’image pour simuler des conditions de stockage ou de transmission.
-
Augmentation textuelle :
- Substitution de mots : Remplacer des mots par leurs synonymes.
- Insertion ou suppression de mots : Ajouter ou retirer des mots aléatoirement.
- Réorganisation de phrases : Changer l’ordre des mots ou des phrases.
- Traduction aller-retour (back-translation) : Traduire le texte dans une autre langue puis le re-traduire en langue originale.
- Paraphrase : Réécrire le texte avec des phrases différentes mais de même sens.
- Changement de registre de langue : Modifier le niveau de formalité ou de technicité du texte.
-
Techniques mixtes :
- Génération de textes via modèles de langage : Utiliser des modèles de langage pour créer de nouveaux textes.
- Combinaison de portions de textes différents : Mélanger des parties de différents textes.
- Remplacement d’entités nommées : Substituer des noms propres par d’autres noms propres.
8. Apprentissage par transfert et fine-tuning
8.1 Principe de l’apprentissage par transfert
Réutiliser un modèle pré-entraîné sur une tâche similaire pour gagner du temps et des ressources. Avec l’apprentissage par transfert, nous prenons un modèle pré-entraîné et le réentraînons sur une tâche qui a une certaine similitude avec la tâche d’entraînement initiale.
Une bonne analogie pour cela est un artiste qui est compétent dans un médium, comme la peinture, et qui souhaite apprendre à pratiquer dans un autre médium, comme le dessin au charbon. On peut imaginer que les compétences acquises en peinture seraient très précieuses pour apprendre à dessiner au charbon.
8.2 Étapes clés
- Gel du modèle (Freezing) :
- Blocage des poids des couches initiales pour préserver l’extraction de motifs génériques (structures grammaticales dans le traitement du langage naturel ou fréquences et amplitudes dans la reconnaissance vocale).
- Ajout de couches Spécialisées :
- Remplacement de la couche de sortie originale par des couches adaptées aux nouvelles classes.
- Entraînement initial :
- Apprentissage uniquement des nouvelles couches ajoutées, avec un taux d’apprentissage modéré.
8.3 Phase de fine-tuning
- Dégel : Libération des dernières couches du modèle pré-entraîné.
- Réentraînement :
- Taux d’apprentissage très faible pour ajuster finement les poids sans dégrader les connaissances existantes.
- Surveillance accrue du surapprentissage via des données de validation.
![]()
9. Modèle de détection de phishing (Google colab)
Après avoir exploré ces concepts clés, il est temps de passer à la pratique et d’appliquer ces principes à un cas concret.
Ce notebook propose une approche pour détecter les tentatives de phishing. Il utilise la bibliothèque Hugging Face Transformers et s’appuie sur le modèle ModernBERT-base, une version optimisée de BERT pour le traitement du langage naturel.
9.1. Installation des bibliothèques et chargement des données
Les dépendances nécessaires sont installées, le jeu de données est ensuite téléchargé depuis la plateforme Hugging Face qui propose de nombreux datasets déjà prêts à l’emploi pour l’entraînement de modèles NLP.
Notre jeu de données se compose de 20 300 textes. Il est relativement équilibré, avec 62 % de textes de non-phishing et 38 % de textes de phishing. Pour l’entraînement de notre modèle, nous utiliserons 80 % de ces données, soit 16 240 textes, et nous garderons les 20 % restants, soit 4 060 textes, pour tester et évaluer les performances de notre modèle.
Pour trouver des datasets :
- Hugging Face Datasets : https://huggingface.co/datasets
- Kaggle Datasets : https://www.kaggle.com/datasets
9.2. Préparation du modèle et des paramètres d’entraînement
ModernBERT est une version améliorée de BERT, un modèle de langage populaire développé par Google. Il offre plusieurs avantages par rapport à BERT, ce qui en fait un choix plus attrayant pour de nombreuses applications de traitement du langage naturel :
| Caractéristique | BERT | ModernBERT |
|---|---|---|
| Efficacité | ||
| Vitesse | Plus lent | Plus rapide (jusqu’à 4x) |
| Taille du modèle | Plus grand | Plus petit |
| Ressources nécessaires | Plus importantes | Moins importantes |
| Précision | ||
| Performances | Bonnes | Égales ou supérieures |
| Gestion du contexte | Bonne | Meilleure |
| Facilité d’utilisation | ||
| Adaptabilité | Bonne | Très bonne |
| Autres avantages | ||
| Gestion des longues séquences | Limitée | Améliorée (jusqu’à 8192 tokens) |
Les principaux hyperparamètres sont :
- MAX_LENGTH : Longueur maximale des textes traités (512 tokens)
- BATCH_SIZE : Nombre d’exemples par lot (16)
- NUM_EPOCHS : Nombre de cycles d’entraînement (3)
9.3. Tokenization et entraînement du modèle
Les textes sont tokenisés à l’aide du tokenizer spécifique à ModernBERT-base, puis le modèle est entraîné pour distinguer les textes malveillants des textes sûrs.
9.4. Évaluation et tests
Une fois entraîné, le modèle est testé sur un jeu de validation pour mesurer ses performances en termes de précision et d’exactitude. Cette étape vérifie son efficacité pour détecter les tentatives de phishing par rapport à de nouvelles données jamais vues.
9.5. Résultats
Après avoir terminé l’entraînement, mon modèle a atteint une précision de 98,6%, ce qui est un excellent résultat.

Cependant, lors de la phase de test avec des données réelles, c’est-à-dire des messages de phishing que le modèle n’avait jamais vus auparavant, il n’a détecté que 9 messages sur 10. Les erreurs du modèle peuvent être dues à une combinaison de facteurs liés aux données d’entraînement, au choix du modèle, à son entraînement et à son utilisation.
Cependant, pour mes besoins de tests, je trouve cela amplement suffisant et laisse aux lecteurs courageux qui sont arrivé jusqu’ici le soin d’explorer davantage ces aspects.
10. Conclusion
Ce cours proposé par NVIDIA m’a fourni une base solide pour comprendre et appliquer les principes du Deep Learning, depuis les fondamentaux jusqu’aux techniques avancées.
En mettant en pratique ces concepts dans un projet concret, tel que la détection de phishing, j’ai pu observer directement l’impact de ces techniques sur des problèmes réels. Les modèles ne sont jamais parfaits et des erreurs peuvent toujours survenir, mais l’important est de s’en rendre compte et de continuer à apprendre.
Mes notes prennent fin ici sur ce sujet. La suite pour moi est un autre cours de NVIDIA, Exploring Adversarial Machine Learning, qui me permettra d’apprendre une méthodologie pour tester, évaluer et rapporter les vulnérabilités et menaces de sécurité des systèmes ML.
Glossaire
- Convergence : État atteint lorsqu’un modèle cesse d’apporter des améliorations significatives à ses performances au fil des itérations d’entraînement.
- Gradient : Vecteur indiquant la direction et l’intensité du changement nécessaire pour ajuster les poids du réseau et minimiser l’erreur lors de l’apprentissage.
- Neurones : Unités de base d’un réseau de neurones artificiel, responsables du traitement des informations en appliquant des transformations mathématiques.
- Régularisation : Techniques utilisées pour éviter le surapprentissage (overfitting) en pénalisant des modèles trop complexes ou en limitant les valeurs des poids.
- Taux d’apprentissage : Paramètre qui contrôle l’ampleur des ajustements apportés aux poids d’un modèle lors de l’entraînement. Un taux trop élevé peut empêcher la convergence, tandis qu’un taux trop faible ralentit l’apprentissage.
- Vanishing gradient : Phénomène où le gradient devient trop faible lors de la rétropropagation, ralentissant ou empêchant l’apprentissage des couches profondes d’un réseau de neurones.